Rapport d’activité 2017 de l’association Open Food Facts
Nous vous invitons à nous rejoindre pour relever ces défis avec nous, et à venir en discuter lors des Journées OFF et de l’Assemblée Générale de l’association Open Food Facts les 7 et 8 avril 2018 à Paris.

Anca aux Geek Faeries 2017
Open Food Facts en quelques chiffres
En 2017, la base de produits alimentaires collaborative, libre et ouverte Open Food Facts a presque quadruplé de taille, passant de 109 000 produits a 396 000 produits entre janvier 2017 et décembre 2017 ! Une grande partie des nouveaux produits ont été ajoutés via l’import d’autres bases libres (en particulier celle de l’USDA aux Etats Unis avec 175 000 produits), mais la collecte citoyenne s’est également accélérée grâce aux 7500 contributeurs d’Open Food Facts mais également aux très nombreux (plus de deux millions !) utilisateurs de l’application Yuka. Cette application (utilisant Open Food Facts et permettant à ses utilisateurs d’y contribuer) ont ont photographié et saisi les ingrédients et valeurs nutritionnelles de plus de 100 000 nouveaux produits.
Les réutilisations de la base de données Open Food Facts sont également de plus en plus nombreuses, nous avons compté plus de 100 réutilisations très diverses : applications mobiles, services web, produits, articles de recherche.
Cette croissance très rapide du nombre de produits et de réutilisations ouvre de nouvelles perspectives et opportunités, mais présente également de nouveaux défis qu’il nous faut maintenant relever.
Croissance et mise à jour de la base de produits
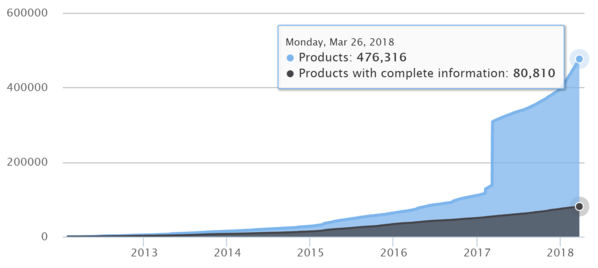
De 2012 à 2016, l’ajout de produits provenait quasiment exclusivement de la collecte citoyenne (crowdsourcing) des contributeurs d’Open Food Facts : collecte de photos des produits, listes d’ingrédients et tableaux nutritionnels via l’application mobile Open Food Facts (et également l’application tierce Date Limite), et saisie des ingrédients et des valeurs nutritionnelles via le formulaire web sur le site Open Food Facts.
En 2017, la collecte citoyenne des contributeurs d’Open Food Facts continue de plus belle et 3 nouvelles sources de photos et de données produits ont été mises en place :
Import d’autres bases de produits sous licence libre
En février 2017, nous avons importé les données du projet OpenFood.ch / FoodRepo de l’Ecole Polytechnique de Lausanne, contenant 12 000 produits du marché suisse. Les photos et données ont été en majorité collectées par des étudiants.
En mars 2017, nous avons également importé la base NDB du ministère américain de l’agriculture (USDA) contenant les données de 175 000 produits vendus aux Etats-Unis. Ces données n’étaient malheureusement pas accompagnées de photos.
Ces imports ont permis d’obtenir une très bonne représentation des marchés suisses et américains.
À ce jour nous avons identifié une autre base (celle du magazine Bon à Savoir en Suisse) que l’on pourrait importer dans Open Food Facts.
Défi : au delà de l’import ponctuel se pose la question de la synchronisation des données avec ces autres bases.
Ajout massif de photos et données via Yuka

En France, l’application Yuka qui utilise les données d’Open Food Facts connait un essor fulgurant. Elle a convaincu près de 2 millions d’utilisateurs qui ont adopté l’application Yuka pour iOS ou Android. Yuka permet également à ses utilisateurs de contribuer des photos et des données, ce qui a permis l’ajout ou la mise à jour de 175 000 produits, et le nombre de produits ajoutés chaque mois à travers Yuka continue d’augmenter.
Cet ajout massif est un moyen formidable d’étendre le nombre de produits de la base, mais il nous faut gérer des problèmes de qualité des données entrées. En particulier Yuka utilise la reconnaissance optique de caractères pour les listes d’ingrédients, ce qui occasionne beaucoup d’erreurs, qui multipliées par le grand nombre de produits sont trop nombreuses pour être corrigées par les contributeurs d’Open Food Facts.
Grâce à Yuka, Open Food Facts a énormément gagné en quantité, mais la qualité s’est dégradée, entraînant un gros sucroit de travail et une grande frustration pour beaucoup de contributeurs d’Open Food Facts.
Défi : L’amélioration de la qualité des données collectées via les applications tierces est donc une grande priorité pour 2018. Pour y arriver, nous pouvons compter sur la pleine collaboration de l’équipe de Yuka avec qui nous échangeons très régulièrement et qui a déjà mis en place de nombreuses améliorations à notre demande. Et nous plaçons également de grands espoirs dans les technologies d’intelligence artificielle qui se démocratisent et nous sont maintenant accessibles. (voir chapitre sur l’Amélioration de la qualité des données).
Import en direct des producteurs
En 2017, nous avons travaillé avec les équipes de Fleury Michon pour obtenir directement les photos et données de leurs produits sous licence libre. Cela ne présente que des avantages car c’est l’assurance d’obtenir des données complètes, correctes, et à jour pour l’ensemble des produits de la marque, ainsi que des photos de grande qualité (ce qui au delà de l’aspect esthétique permet également des applications de reconnaissance visuelle de produits sans scanner les codes barre). Fleury Michon nous fournit maintenant un flux XML contenant les données de ses produits, que nous avons ainsi pu ajouter en bloc dans la base.
Nous avons été depuis contactés par plusieurs autres fabricants et distributeurs qui sont enthousiasmés par Open Food Facts et qui sur le principe sont prêts à nous fournir leurs données et photos.
Défi : les premiers imports ont demandé beaucoup de temps pour rencontrer et accompagner les producteurs, mettre en place des scripts d’imports (chaque producteur nous fournit des fichiers de formats différents). Il faut industrialiser ce processus afin de pouvoir obtenir les données en direct de beaucoup plus de producteurs en proposant par exemple un format standard que les producteurs pourraient adopter.
Développement international
Traductions
2017 a été l’année où les fruits des travaux entamés ont commencé à porter leurs fruits à grande échelle.
Crowdin a permis a de nombreuses langues d’être terminées, et la vitesse de déploiement des traductions s’est accélérée, tant sur le serveur que sur les applications mobiles de 2ème génération.
Cela a eu un impact conséquent sur la visibilité d’Open Food Facts dans d’autres langues que le français et l’anglais, et permet d’obtenir les premiers produits dans de nombreux pays.
La traduction et l’extension des taxonomies sont désormais une priorité pour une amélioration de l’expérience internationale. Il est nécessaire de trouver une solution qui permette leur traduction à une vitesse accélérée.
Communautés locales

Pierre en Albanie avec les associations locales d’open data
2017 a été l’occasion de forger la notoriété d’Open Food Facts à l’étranger: import des produits suisses, imports des produits américains ont amorcé Open Food Facts dans ces deux pays. Nous avons aujourd’hui 9000 visiteurs par semaine aux Etats Unis, et 2000 en Suisse.
Au dela de l’utilité immédiate pour les utilisateurs, une presence aux US a réhaussé le statut du projet, avec de nombreux développeurs qui s’intéressent désormais au projet.
Dans le cas de la Suisse, nous sommes allés présenter le projet à deux reprises (pour Open Food et Bon à Savoir), avec à chaque fois des données à la clé, ainsi qu’une notoriété auprès de communautés locales qualifiées (developpeurs attirés par l’alimentation et grand public intéressé)
Nous sommes allé présenter Open Food Facts au FOSDEM, congrès européen de l’open source, avec une présence beaucoup plus visible que les années précédentes: présentation générale du projet, présentation technique dans la salle dédiée à Perl, présence visuelle à travers l’évènement. Nous avons pu y nouer des contacts avec l’équipe du Google Summer of Code, qui ont sans doute aidé dans notre candidature enfin heureuse.
Enfin, nous avons saisi l’opportunité d’une invitation en Albanie pour présenter Open Food Facts dans le cadre d’un projet européen. En plus des participants à ce congrès, issus de nombreux états membres (Grèce, Espagne, Portugal…), nous avons saisi l’occasion pour organiser la première Scan Party en Albanie, avec des contributeurs Wikipedia et Open Street Maps locaux. L’enthousiasme est là, et l’expérience doit être dupliquée ailleurs.
Enfin, à l’horizon, se profile un possible renforcement des communautés locales en Europe, via notre participation au projet européen porté par l’EPFL, résultat concret de la visite en Suisse.
Open Beauty Facts et Open Pet Food Facts

Daenerys aux Geek Faeries : le secret de sa chevelure d’or ? Open Beauty Facts !
Open Beauty Facts est désormais disponible sur Android et iOS avec la fonctionnalité de détection d’ingrédients nocifs. La transparence cosmétique s’accélère. De nombreuses applications sont en train d’éclore, portés par des acteurs privés, l’UFC Que Choisir, ou bien Yuka.
Il est donc important d’assurer une croissance d’Open Beauty Facts pour porter cette transparence: – ajouter le décryptage à grande échelle des fonctions des ingrédients en utilisant la nomenclature INCI – ajouter la fonction de détection des ingrédients problématiques dans la version 2 de l’application, dont les progrès majeurs bénéficient automatiquement à Open Beauty Facts, – lancer des imports en attente (Bon à Savoir) et se rapprocher des industriels pour obtenir des catalogues en plus (nous avons 2 à 3 imports en attente qui contiennent des produits cosmétiques).
Open Beauty Facts et Open Pet Food Facts bénéficient des améliorations logicielles, et des produits ajoutés par les utilisateurs de Yuka, et déplacés manuellement par les modérateurs. Il faudra améliorer le lien entre les bases pour rediriger automatiquement vers la bonne base et empêcher l’ajout de produits cosmétiques dans Open Food Facts et réciproquement.
Améliorations de la qualité
La qualité des données de la base Open Food Facts est d’une importance cruciale. Grâce à des applications tierces comme Yuka et Date Limite qui permettent à leurs utilisateurs d’envoyer des photos et des données, le volume des contributions a été multiplié par 4. Mais les utilisateurs de ses applications n’ont pas forcément tous la même motivation et la même attention que les contributeurs d’Open Food Facts, il y a donc plus d’erreurs (listes d’ingrédients reconnues automatiquement par l’OCR mais fausses et non corrigés, informations nutritionnelles incomplètes etc.).
Voici comment nous pensons remédier à ces problèmes pour résoudre ces problèmes de qualité des données :
Détection des erreurs
Nous avons commencé à mettre en place des algorithmes de détection d’erreurs, ou de détection d’erreurs probables.
Erreurs dans les informations nutritionnelles
Nous avons mis en place des vérifications de base, afin de vérifier qu’il n’y pas de valeurs nutritionnelles abberantes (par exemple sucres supérieurs aux glucides, ou somme des nutriments supérieure à 100g).
Un projet mené par des étudiants de l’ENSAE est en cours pour identifier les produits qui ont des valeurs nutritionnelles très différentes des autres produits de la même catégorie.
Erreurs dans les listes d’ingrédients
Nous avons commencé à créer une taxonomie d’ingrédients, pour lister tous les ingrédients possibles (ou du moins une très grande majorité). Cette liste est en cours de création, mais elle est déjà utilisée pour repérer les listes d’ingrédients problématiques, qui contiennent de nombreux ingrédients inconnus.
La création de la taxonomie d’ingrédient est un gros travail, elle est pour l’instant essentiellement en français, mais nous allons la rendre multilingue, comme les autres taxonomies comme celle des catégories.
En plus de permettre la détection d’erreurs, la taxonomie des ingrédients sera également très utile pour beaucoup d’autres choses, comme par exemple la traduction automatique des listes d’ingrédients, la détermination du caractère végétarien ou non d’un produit etc.
Photos floues
Ce n’est pas encore en place, mais nous pourrions essayer d’identifier les photos floues, afin de les refuser et de demander aux utilisateurs d’essayer de prendre une meilleure photo.
Que faire des signalements d’erreurs ?
Nous détectons actuellement beaucoup plus d’erreurs probables que nous ne pouvons manuellement vérifier et corriger, en particulier pour les listes d’ingrédients.
Nous avons commencé à mettre en place des outils pour accélérer au maximum les corrections (comme par exemple l’édition en place de la liste des ingrédients sur le site web, sans devoir charger le formulaire de modification de produit), mais face au volume de nouveaux produits, cela ne suffit pas.
Nous allons travailler avec les développeurs des applications (notamment Yuka) pour essayer de détecter les erreurs en temps réel, au moment même de la contribution, pour pouvoir alerter les utilisateurs et leur demander de corriger leur propre contribution, ou de prendre une meilleure photo etc.
L’autre voie d’amélioration est de travailler sur l’élaboration de méthodes plus fiables d’extraction automatique des données depuis les photos des produits, c’est l’objet de la partie suivante.

Le robot open source inmoov, en train de vérifier les données d’une bouteille d’eau dans la base Open Food Facts ? 🙂
Photo prise et partagée par Jean-Pierre Dalbéra sur Flickr, licence Creative Commons CC-BY
Extraction automatique de données depuis les photos
A ce jour, la quasi-totalité des informations de la base Open Food Facts (nom du produit, marques, labels, catégories, ingrédients, informations nutritionnelles etc.) sont saisies à la main par les contributeurs d’Open Food Facts et les utilisateurs d’applications tierces. L’exception notable est la liste d’ingrédients des produits ajoutés via Yuka qui est reconnue automatiquement (OCR) mais qui contient souvent des erreurs.
La saisie des informations est un travail long et fastidieux. Avec la multiplication du nombre de nouveaux produits, la proportion de produits avec des fiches complètes est passée de 50% en janvier 2017 à 25% en janvier 2018.
Les technologies d’intelligence artificielle et de vision par ordinateur ont fait d’énorme progrès ces dernières années, et elles sont pour la plupart disponibles en open source (comme par exemple l’outil d’apprentissage automatique Tensor Flow développé par Google).
Nous pouvons utiliser la base existante créée par les utilisateurs pour entrainer ces algorithmes d’apprentissage pour que la saisie des informations depuis les photos devienne de plus en plus automatique, et ainsi économiser un long et fastidieux travail manuel aux contributeurs, et augmenter la quantité et la qualité des données.
Liste d’ingrédients
Création d’une taxonomie d’ingrédients
La création d’une taxonomie d’ingrédients connus permet de créer des dictionnaires d’ingrédients qui peuvent être utilisés par les algorithmes de reconnaissance optique de caractères (OCR), comme Tesseract.
OCR de la liste d’ingrédients
Nous utilisons aujourd’hui Tesseract (disponible dans le formulaire de modification de fiche), mais il s’agit de la version non configurée. Elle peut être enrichie avec des dictionnaires d’ingrédients pour améliorer la reconnaissance.
D’autre part nous pouvons améliorer les photos pour que la reconnaissance soit plus facile (suppression des différentes de luminosité, redressement etc.).
Informations nutritionnelles
Les informations nutritionnelles sont aujourd’hui saisies manuellement, ce qui occasionne parfois des erreurs de saisie (valeurs mal placées), et ce qui est surtout très long.
Nous pouvons développer des algorithmes pour repérer automatiquement les tableaux nutritionnels (présence de lignes), et ensuite utiliser de l’OCR pour récupérer les valeurs nutritionnelles.
Par rapport à la liste d’ingrédients, il est possible que des méthodes d’OCR moins classiques que Tesseract comme les réseaux neuronaux permettent de meilleurs résultats pour extraire les chiffres.
Marques, labels
Les réseaux neuronaux sont bien adaptés à la reconnaissance de logos de marques, de labels etc. Nous devrions pouvoir repérer ces logos relativement facilement dans les images.
Catégories
Une fois les marques, labels, ingrédients etc. extraits, il devrait être possible de classer automatiquement les produits dans les catégories de notre taxonomie, ou tout du moins d’obtenir des catégories probables que nous pourrions demander aux utilisateurs de confirmer (« Ce produit est il un biscuit au chocolat ? »).
Développement des imports en direct des producteurs
Comme déjà mentionné dans la partie sur la croissance de la base, l’ajout de photos et données en direct des producteurs permet d’obtenir des données correctes à 100%.
Vérification des fiches et verrouillage des fiches vérifiées
Pour les données en provenance des producteurs, nous avons un système d’alerte lorsque les données sont modifiées. Nous pourrions étendre ce système pour refuser certaines modifications lorsqu’on détecte qu’elles ont un certain risque d’être non qualitatives. Le système pourrait également être étendu aux fiches produits dont les informations ont été vérifiées par les contributeurs expérimentés.
Réutilisations
Plus de 100 réutilisations !
Nous avons compté plus de 100 réutilisations différentes des données d’Open Food Facts. Nous découvrons la plupart par hasard : les données étant libres et ouvertes, les réutilisateurs ne sont pas tenus de nous signaler leurs réutilisations, il y en a donc certainement beaucoup d’autres.
Nutri-Score
Depuis fin 2014, le Nutri-Score (anciennement note 5 couleurs ou 5-C) est disponible sur les produits de la base Open Food Facts. Après 3 ans de bataille, le Nutri-Score a été finalement adopté en France. C’est un étiquetage optionnel, au choix des producteurs. Une trentaine d’entre eux se sont déjà engagés à le faire figurer sur l’emballage de leurs produits, et nous en observons de plus en plus en rayon, même si cela reste pour l’instant assez limité. Sur Open Food Facts, le Nutri-Score est calculé et affiché pour 85 000 produits du marché français, et nous espérons que cela contribue à populariser le Nutri-Score et encouragera plus de producteurs à l’adopter. Nous affichons également le Nutri-Score pour les produits du monde entier.

Collaboration avec l’Equipe de Recherche en Epidémiologie Nutritionnelle (EREN)
Nous travaillons avec l’équipe de l’EREN (à l’origine du Nutri-Score) qui a déjà utilisé les données d’Open Food Facts pour publier des articles de recherche, et qui souhaite également les utiliser pour de nouveaux projets (étude Nutri-Net et recherche sur l’effet des additifs alimentaires).
Nous sommes ravis de cette collaboration qui montre qu’Open Food Facts ne se limite pas au décryptage et à la comparaison des produits alimentaires pour soi-même, mais permet également de contribuer à l’amélioration de la santé publique.
Nouvelles fonctionnalités
Plus de 200 améliorations (petites et grandes) et corrections ont été apportées à Open Food Facts en 2017.
Parmi celles-ci :
– Support de plusieurs tableaux nutritionnels pour le produit tel que vendu et le produit préparé (purée en flocons etc.)
– Meilleure reconnaissance des additifs et mise en place de taxonomies pour les vitamines et minéraux
– Ajout de Google Cloud Vision pour la reconnaissance automatique des ingrédients
– Amélioration de la prise en charge des traductions (Crowdin à la place du wiki)
– Support du HTTPS / SSL
Applications mobiles
2017 a montré, avec Yuka, que le mobile est clé pour collecter de la donnée, au dela des classiques 3 photos. Il s’agit de fournir des outils efficaces et modernes à la communauté d’Open Food Facts, et permettre une extension internationale dans les pays où le seul canal d’information sur les aliments est le mobile, dans des conditions de réseau qui ne sont pas forcément optimales.
Nous devons :
- inclure un système d’OCR de la liste d’ingrédients, d’extraction des labels et logos, et de modération des visages. L’avenir d’Open Beauty Facts en dépend assez largement, avec des listes d’ingrédients complexes à saisir à la main.
- permettre l’édition native complète depuis mobile afin de corriger aisément les produits, en mobilité, même hors connexion Cela a le potentiel d’augmenter de moitié les contributions, comme plus de 50% de la base d’utilisateurs est désormais mobile.
2017 a commencé en creux pour les applications mobiles. Le développement s’est accéléré avec l’arrivée d’un nouveau développeur iOS (Tovkal) et surtout le Google Summer Of Code qui a amené un nombre sans précédent de volontaires, qui ont fiabilisé l’application Android, et développé nombre de fonctionnalités qui soient manquaient par rapport à la V1, soit étaient réclamées par les utilisateurs. D’autres fonctionnalités qui correspondaient à des objectifs plus lointains ont également été developpées.
Pierre est confiant sur une migration pour Android, et iOS, qui sera facilitée par le fait d’avoir un étudiant à plein temps pour régler d’éventuels bogues.
Communication externe
Présentations

Pierre présente Open Food Facts en Suisse
Comme chaque année, en 2017 nous avons répondu présents à toutes les invitations pour présenter Open Food Facts, en participant à des conférences et tables rondes, ou en tenant des stands sur des salons :
- Hackathon à Lausanne (Pierre)
- Conférence au Salon du Livre à Genève (Stéphane)
- Geek Faeries (Anca, Ludovic et Pierre)
- Atelier sur les Biens Communs pour les responsables d’Espaces Publics Numériques (Stéphane)
- Forum de la Culture à Créteil (Minouche)
- Open Source Summit (Pierre et Stéphane)
- Conférence lors des 50 ans du Centre de Sociologie des Organisations de Sciences Po (Stéphane)
- FOSDEM (Anca et Pierre)

Stéphane au Paris Open Source Summit
Open Food Facts et Yuka
En 2017, le formidable essor de Yuka a eu tendance à éclipser Open Food Facts dans les médias, et Yuka est aujourd’hui bien plus connu du grand public qu’Open Food Facts. Cette différence de reconnaissance occasionne de la frustration pour beaucoup de contributeurs d’Open Food Facts qui ont parfois le sentiment que Yuka augmente leur travail de vérification et de correction des fiches tout en en récoltant les fruits.
Il est important de rappeler que le succès de Yuka, c’est aussi le succès d’Open Food Facts. C’est parce que nous souhaitions multiplier l’impact de la base Open Food Facts que nous l’avons conçue comme une base ouverte et libre, justement pour permettre à tous d’utiliser les données pour tous types d’usage. Aujourd’hui il y a plus de 100 réutilisateurs des données, et outre le fait que Yuka est l’une des plus grandes sources de nouveaux produits, nous pouvons être heureux et fiers qu’ils réussissent à avoir un tel impact.
Mais Open Food Facts ne se limite pas à l’utilisation qu’en fait Yuka : il nous appartient de continuer à développer les autres usages de la base, comme sa réutilisation par les équipes de recherche qui oeuvrent pour la santé publique comme celle du Professeur Hercberg. Et il nous appartient également de faire connaître ces usages, pour les multiplier, pour accroître le nombre des contributeurs et participants au projet Open Food Facts, et également pour que le projet soit plus connu et reconnu. Les contributeurs d’Open Food Facts sont bénévoles, ils méritent d’être reconnus.
Communication interne
Slack
Depuis 3 ans, nous utilisons la plateforme de discussion en ligne Slack pour échanger entre tous les membres du projet (contributeurs, développeurs, réutilisateurs etc.). Nous y sommes déjà 1800. Si vous n’êtes pas encore inscrit, rejoignez-nous !
Réunions à la Fondation pour le Progrès de l’Homme
Les membres d’Open Food Facts qui habitent en région parisienne sont très souvent présents aux soirées de contribution aux projets libres qui ont lieu à Paris le jeudi soir à la Fondation pour le Progrès de l’Homme. Si vous habitez en région parisienne, venez à notre rencontre (pour être sûr qu’on soit là, rejoignez le canal #paris sur Slack).
Si vous habitez loin de Paris : pourquoi ne pas organiser une réunion Open Food Facts près de chez vous ? Nous pouvons vous aider à identifier les autres contributeurs de votre région et à faire connaître votre événement.
Des ressources humaines au service d’un projet citoyen
Depuis 2012, le projet Open Food Facts est porté entièrement par des citoyens bénévoles regroupés en association 1901. Le projet repose sur la collecte citoyenne pour alimenter la base (sur le modèle d’autres projets citoyens comme OpenStreetMap et Wikipédia), et également sur des bénévoles pour la gestion et le développement technique.
Cette organisation frugale est à la fois un atout et une faiblesse. C’est un atout car le project peut fonctionner quasiment sans financement (pas de salaires, pas de locaux) ce qui au risque de surprendre le rend plus pérenne. Mais si l’on peut faire autant avec aussi peu, pourrait-on faire encore bien plus avec des ressources supplémentaires dédiées au projet ?

Contributeurs
Plus de 7800 contributeurs ont ajouté des produits via l’application ou le site web Open Food Facts (sans compter les utilisateurs d’applications tierces). Les contributeurs ajoutent des nouveaux produits, complètent et corrigent les fiches, mais ils font également beaucoup d’autres choses qui rendent Open Food Facts plus riche et plus utile, comme par exemple l’élaboration des taxonomies (des catégories, des ingrédients etc.) qui permettent de construire de nouveaux services et de rendre les données plus utiles. Les contributeurs sont également les ambassadeurs du projet, ils présentent le projet, et permettent ainsi de trouver de nouveaux contributeurs et réutilisateurs. Ils sont également la première source d’idées d’améliorations, d’utilisations possibles des données etc.

Pierre ne manque jamais une occasion de présenter le projet Open Food Facts 🙂
Il est important que nous trouvions les moyens de rendre la contribution de nouveaux produits et la saisie et correction des informations plus facile, rapide et automatique (avec notamment des améliorations de l’expérience utilisateur et la mise en oeuvre de plus d’automatisation et d’algorithmes d’intelligence artificielle) pour qu’ils puissent se concentrer sur les parties les plus valorisantes du projet.
Développeurs
La base de données, le serveur web, l’API et les applications mobiles sont développées et maintenues par une petite dizaine de développeurs bénévoles.
L’absence de ressources dédiées rend le développement et le déploiement de nouvelles fonctions très chaotique. Ainsi les applications mobiles officielles sur Google Play et l’App Store n’ont pour ainsi dire pas du tout évolué depuis leur lancement en 2012 et 2013.
Pour la partie base de données et serveurs, certaines évolutions comme l’historicisation des différentes évolutions des produits d’une année à l’autre ont été spécifiées depuis plusieurs années mais toujours pas développées.
De même, mettre en oeuvre des algorithmes d’intelligence artificielle et d’extraction automatique de données depuis les photos représenterait un énorme potentiel de gain de temps pour les contributeurs, mais n’a jusqu’ici pas été abordé.
Des stagiaires rémunérés pour Open Food Facts grâce au Google Summer of Code

Grâce à Anca et Pierre, Open Food Facts candidate depuis plusieurs années au programme Google Summer of Code, et pour la première fois, Open Food Facts est l’une des organisations acceptées pour le Google Summer of Code 2018 ! Concrètement, cela va permettre à des développeurs étudiants de travailler pendant 3 mois sur des projets liés à Open Food Facts tout en étant rémunérés par Google. Nous ne savons pas encore combien de projets seront financés par Google pour Open Food Facts (probablement entre 2 et 10), mais 250 étudiants ont rejoint le canal #summerofcode sur Slack et nous avons reçu une cinquantaine de propositions de projets.
C’est une formidable opportunité pour Open Food Facts, mais c’est aussi un grand travail pour accueillir, guider et répondre à tous les candidats, et ensuite pour encadrer les projets retenus.
Gestion, communication, développement des réutilisations, développement international
Le conseil d’administration de l’association répond aux sollicitations que nous recevons quotidiennement de la part d’utilisateurs, de réutilisateurs existants ou potentiels, de producteurs et distributeurs, de chercheurs etc.
Il est de plus en plus difficile de répondre (et de suivre) toutes les sollicitations, en particulier toutes celles qui demandent des développements logiciels.
C’est bien sûr frustrant pour toutes les personnes à qui nous tardons à répondre (ou parfois ne répondons pas), c’est aussi frustrant pour les membres du CA qui se disent qu’ils devraient faire plus, tout en devant arbitrer avec leur vie personnelle et professionnelle.
Ressources humaines dédiées au projet
Open Food Facts a un impact grandissant, mais nous avons des difficultés grandissantes pour faire face au surcroit de travail que cette croissance implique. Il serait donc utile d’étudier la possibilité d’allouer des ressources humaines dédiées au projet, qui puissent travailler à plein temps au projet, en étant payées.
Cela permettrait d’adresser les défis que nous avons identifiés dans ce rapport d’activité de façon stratégique et prioritisée. Sans ressources dédiées, il est impossible de planifier et prioritiser : les bénévoles font ce qu’ils peuvent, quand ils peuvent, et ne peuvent pas prévoir à l’avance leur disponibilité (ou tout simplement leur envie) pour le projet. Les choix sont alors tactiques, faits avec les ressources disponibles sur le moment, ce qui permet de résoudre au moins ponctuellement les sujets brûlants, mais pas toujours de mettre en place les bonnes solutions. Une équipe dédiée permettrait d’être proactif et pas seulement réactif.
Au delà de la gestion de la croissance, une équipe dédiée suffisamment grande permettrait également d’étendre le projet dans de nouvelles directions (déploiement international accéléré, extension à de nouveaux types de produits comme les cosmétiques avec Open Beauty Facts, nouveaux services et applications (par exemple dans le domaine de la lutte contre le gaspillage) etc.
Une équipe dédiée impliquerait bien évidemment un budget et donc un financement bien supérieur à celui avec lequel nous fonctionnons actuellement.
![]()
Financement de l’association
En 2017, l’association a dépensé 943 euros (hébergement du serveur et 2 billets de train pour participer à des événements), et à reçu 723 euros de dons individuels. (les comptes sont disponibles en ligne au format PDF et ODS (LibreOffice Calc))
Nous avons peu fait la promotion des dons et pouvons très probablement financer entièrement l’hébergement du serveur par les dons. D’autre part un hébergeur semble prêt à nous héberger gratuitement.
Nous pouvons donc raisonnablement continuer le fonctionnement (basé complètement sur le bénévolat) et le financement actuel de l’association.
Si nous souhaitons mettre en place une équipe dédiée, il faudra par contre trouver d’autres sources de financement.

Ressources possibles
Dons individuels
Les dons individuels représentent actuellement moins de 1000 euros par an. La plupart sont exceptionnels, mais le recurrent est une option.
Dons et subventions d’entreprises ou fondations privées
Pour préserver notre indépendance et prévenir tout conflit d’intérêt, Open Food Facts n’accepte pas de dons d’entreprises ou fondations liées à des producteurs ou distributeurs du domaine de l’alimentaire.
Il pourrait être envisageable que d’autres entreprises financent Open Food Facts.
Subventions publiques
Les données sur les produits alimentaires sont d’intérêt public, et Open Food Facts oeuvre pour la santé publique. Il pourrait être légitime de prétendre à des subventions publiques.
Appels à projets
Nous avons répondu ces dernières années à plusieurs appels à projets comme le « Google Impact Challenge » ou « La France s’engage ». Nous avons été parfois parmi les candidats finalistes, mais nous n’avons pas été sélectionnés.
Début 2018, nous participons à un consortium pour répondre à un appel à projet européen.
Recherche de financement
Il est important de noter que la recherche de financement est une activité qui demande beaucoup de temps, pour identifier les financements possibles, monter des dossiers de demandes de subventions, répondre à des appels à projets, et dans le cas où les subventions sont accordées ou les projets acceptés, gérer tout le suivi.

Conclusion
2017 a été une année de très forte croissance notamment grâce à l’essor fulgurant de Yuka en France, mais aussi à l’import d’autres bases de données et à l’ajout de données en direct des producteurs. Cette forte croissance continue de plus belle en ce début 2018 mais est également source de problèmes de qualité de la donnée. Des solutions pour améliorer la qualité ont été identifiées et doivent maintenant être mises en place. Pour faire face aux défis induits par cette croissance, il serait très utile qu’Open Food Facts puisse s’appuyer non seulement sur les contributeurs bénévoles, mais aussi sur des ressources humaines dédiées au projet. Financer ces personnes dédiées au projet est en soi-même un autre défi. Tous ces défis sont des bonnes choses : ils montrent le succès et l’impact grandissants du projet Open Food Facts et ils représentent autant d’opportunités d’amélioration pour multiplier encore cet impact. Rejoignez-nous pour les relever !
