
Open Prices: 200,000 prices and beyond
We’re excited to announce that more than 200,000 prices have been published on Open Prices!

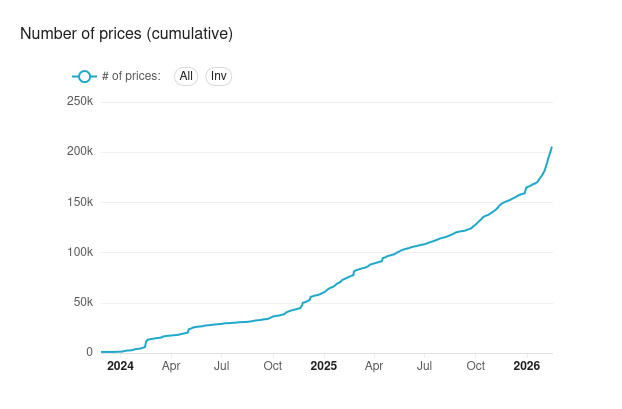
Since October 2025, we’ve witnessed an acceleration in the number of contributions sent to Open Prices, allowing us to reach this 200k milestone sooner than expected. Many thanks to all Open Prices contributors, without whom nothing would have been possible!
This announcement is also the opportunity for us to share what we’ve been working on in the past year and what future directions we consider for the project.
Funding
We’re lucky to be supported by the NLnet foundation, through its NGI Zero Commons program. Thanks to NLnet support, we were able to bring many improvements and new features to Open Prices in the last 8 months. Below is a recap of what we’ve been working.
Past work
Moderation and reporting
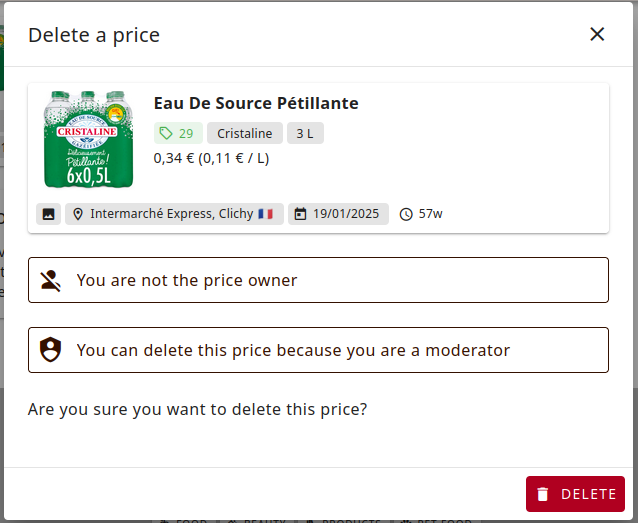
All reports go to a moderation page visible only by moderators. Moderators form a new special group that have the ability to update and delete prices or proofs.
In order to make sure we didn’t lose any information due to a human error made by a moderator, we now keep track of the history of prices and proofs, by saving all versions in the database.
Detect and prevent price and proof duplicates
Due to some bugs or user error, images are sometimes uploaded several times with the same information, creating duplicates in the Open Prices database. We now have a duplicate detection system that automatically rejects duplicate proofs. Duplicate prices are kept but marked with a special duplicate flag, so they can be filtered on the Open Prices website (this latter feature is not yet available).
Improving the price tag extraction model
We use AI to make price addition more efficient by automating repetitive tasks. One of the most popular workflows to add prices is the following:
- contributors upload photos taken in a supermarket, where price tags are visible
- a first computer vision model detects all price tags present on the photo
- a second model analyzes each detected price tag and extracts relevant information such as the price and the barcode
- contributors just have to confirm that the extracted data is correct on a “validation” page
We currently use Gemini 3 Flash, a large language model developed by Google, as the AI that takes care of extracting data from price tag images. We wanted to try training our own model to replace Gemini. Having our own in-house model offers many benefits, including:
- not being tied to LLMs providers: we’re safe from model deprecation or API price increase
- decreasing the environmental impact of our use of AI: by training the model on our own data, we can use much smaller models that require less resources to run.
- ensuring the model is always available: we’re indeed experiencing frequent rate-limiting on Google Cloud with the Gemini API.
- having a fully open source stack
We’ve successfully trained our own model on this task, taking Qwen3 VL 8B model as a base. The extraction performance of our model is on par with Gemini 2.5 Flash, the model we previously used, but still below Gemini 3 Flash. However, it is much lighter to run: a single GPU with 24GB of VRAM is enough to run it locally.
A detailed post will be published in the coming weeks to present this project in greater depth!
User research
Julia is leading user research on Open Prices, doing discovery interviews with contributors, getting their reaction to proposed features, and iterating on existing feature to make them more intuitive and easier to use. She plans to launch user surveys soon, so if you’re interested in helping improve Open Prices, stay tuned!
What’s coming next?
Many cool features and improvements are in the pipeline, including:
- the addition of a gamification system (with badges) to unlock based on your contribution to Open Prices.
- the detection of abnormal prices
- improvement of the price tag detection model, which detects all price tags on supermarket shelve images
We will also keep improving the user interface to make Open Prices more user-friendly and easier to use!