
How Open Food Facts uses logos to get information on food products
🧂A pinch of context: “logos” ?
Open Food Facts is filled with about 3 million products. Each product has a packaging which is made to attract as many people as possible. To this regard, productors highlight the qualities of their products with flashy and explicit symbols. These symbols are numerous and can give information on the brand of the product, its quality, its composition, the way it was made, in which bean to discard it, etc…
To homogenize all symbols and help consumers to find products that fit them, various institutions have created strict rules for producers to be able to mark their products with specific symbols which we call “logos”. There is thus a huge opportunity 🔥 to get data about products by detecting these logos!
How should Open Food Facts detect them ? Thanks to a mix between technology and contributors, as always!
Raphaël Bournhonesque, a former Open Food Facts contributor who is now part of the permanent team and my internship supervisor, had developed in Robotoff* a system to extract logos from images, convert them into vectors and find the nearest neighbours of each vector. The goal of finding logos’ neighbours was to allow contributors to “annotate” (to categorise manually) massive amounts of logos at the same time through a platform, named Hunger Games 😉.
However, the models and algorithms used back then could not give efficient enough results.
In September 2022, I, an engineering student, joined the team for an internship of 6 months which would be dedicated to logos, and I worked on refactoring this whole process! 🥳
| * What is Robotoff ? Robotoff is a service developed by contributors to help Open Food Facts data processing. Based on the data already available in the database, the goal is to retrieve as much information as possible on each product and to add them to the db. Currently, the updates made by Robotoff come from images analysis, through Optical Character Recognition or more general Computer Vision models. Some updates are applied automatically to the db but some others need manual validation via questions or Hunger Games. To know more about Robotoff, take a look here! 👀 |
🫗 A drizzle of tech: How does logos processing work exactly ?
1️⃣ Extract logos from products images:
Open Food Facts contributors trained a Machine Learning model to recognize logos in images. We put an image as the input of the model and we receive multiple bounding boxes with corresponding scores and classes. The classes on which the model was trained were “brand” and “label”.
You can find the code where the model is called here: Robotoff.import_image.py.
You can try it by using the following API : https://robotoff.openfoodfacts.net/api/v1/images/predict?image_url=[image_url]&models=universal-logo-detector
With the bounding boxes, you can see what are the corresponding logos with the API: https://robotoff.openfoodfacts.net/api/v1/images/crop?image_url=[image_url]&y_min=[y_min]&x_min=[x_min]&y_max=[y_max]&x_max=[x_max] where the coordinates are in the same order as the ones returned by the model in the bounding boxes.
Here is an example of what happens when using these APIs with the following image:
https://images.openfoodfacts.org/images/products/322/982/012/9488/front_fr.194.400.jpg

2️⃣ Convert logos images to Vectors:
Now that we can access logos, we need to vectorise them. For that, we use a pre-trained model from OpenAI called CLIP. Even though the model was initially trained to match images with text, we use only the “computer vision” part of the model to get the embeddings (=logos embedded in a vector space) computed by CLIP for each logo.
We thus have a logo image as input and a vector of dimension 512 as output. The smaller the distance between two vectors is, the more similar the two corresponding logos are.
The save_logo_embeddings function in Robotoff is in charge of applying the model to logos and save embeddings to the Robotoff postgresql database.
You can find a more explicit code here to understand how we use CLIP to generate logos embeddings.
3️⃣ Find nearest neighbours:
To find the nearest neighbors of a logo, we use an “index” to store the embeddings. Once this index is built, we could use the “brute force” 💪 method which consists in computing the distance between the query logo and all the other logos of the db and return the closest ones. That’s the most precise method as it gives us the “true” nearest neighbors. However, this method is too slow to be applied. The time needed to extract the nearest neighbors for each logo when the total amount of logos is 2.5M is around 3s 😴
As we needed a better search time and were ok with having less precision, we decided to use an approximate method. The one that Robotoff uses is called HNSW (hierarchical navigable small world). You can take a look at this article to understand better nearest neighbours search.
Using a HNSW ElasticSearch index, Robotoff is now able to look for the nearest neighbours of each embedding among more than 2.5M vectors with a huge precision (more than 90% of the 100 nearest neighbours returned are among the exact 100 true nearest neighbours) and a short search time of less than 100ms 👏👏👏👏.
You can use the following API to get the nearest neighbours of a logo: https://robotoff.openfoodfacts.org/api/v1/ann/search/[logo_id]?count=[count]
🍯 A spoon of contributions: Where is it used?
No automatic logo categorization is yet implemented in Robotoff. Everything I explained before is made only for Hunger Games.
What is it ? It is an annotation platform developed by a contributor named Alexandre Fauquette which allows everyone to answer check predictions made by Robotoff and to categorise logos.
You can try it. A quick introduction/tutorial will welcome you and you will be able to annotate logos ! 😉
A video tutorial of “How to use Hunger Games ?” should be out soon… ⏳
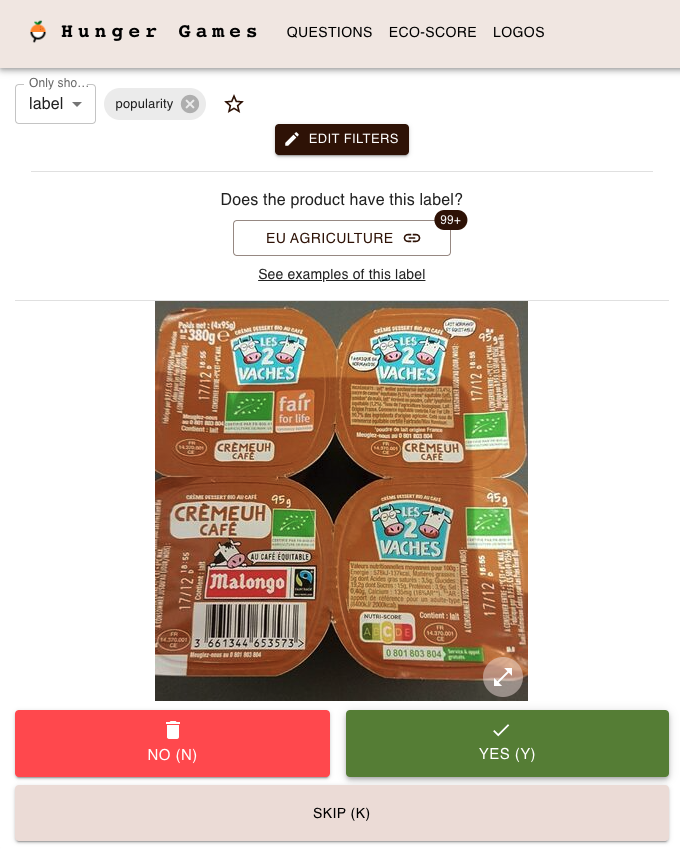
Annotating logos enhance Open Food Facts as it grows the amount of data we have on products and its quality. And thanks to the models and algorithms used in the background, you can be way more powerful and have a greater impact on people daily alimentation 🥰.
Article by Gabriel

No Comments